While working on our research paper titled “High-frequency Trend Prediction of Bitcoin Exchange Rates Using Technical Indicators and Deep Learning Architectures”, we encountered numerous papers and specialized documentation that boasted an accuracy of over 90% for Trend Prediction for Bitcoin trading systems. However, upon closer examination, we found this accuracy to be relatively high in comparison to the performance of profitable and successful models that typically achieve about 60% accuracy. Further investigation revealed a persistent error that was responsible for this inflated accuracy: data leakage.
Time series data is a crucial component of many real-world applications, ranging from finance and economics to weather forecasting and predictive maintenance. Machine learning models trained on time series data require careful consideration to ensure accurate predictions. One critical aspect of building robust models is performing proper cross-validation. However, when handling time series data, there is a unique challenge called “data leakage” that can significantly impact the reliability and performance of these models. In this article, we will explore the concept of data leakage in time series data cross-validations in machine learning and discuss strategies to mitigate this issue.
Understanding Data Leakage:
Data leakage occurs when information from the future leaks into the past during the training and validation process of time series models. In other words, data that should not be available at the time of prediction becomes accessible during the training phase, leading to overly optimistic performance estimates and unreliable models.
Challenges in Time Series Cross-Validation:
Traditional cross-validation techniques like k-fold or stratified sampling are not directly applicable to time series data due to its temporal nature. When dealing with time series data, the order of observations matters, and predictions are made based on the historical context. Applying random shuffling or splitting can introduce severe leakage issues.
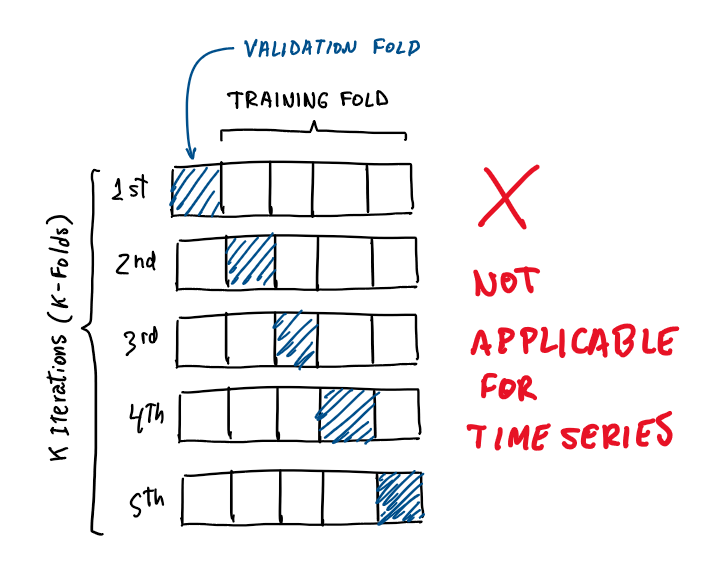
Strategies to Mitigate Data Leakage:
To address data leakage in time series data cross-validations, several techniques can be employed:
Train-Test Split:
Instead of using traditional k-fold cross-validation, a train-test split is commonly employed. The data is divided into a training set containing historical observations and a separate test set containing more recent observations. The model is trained on the training set, and performance is evaluated on the test set, providing a realistic assessment of its predictive abilities.
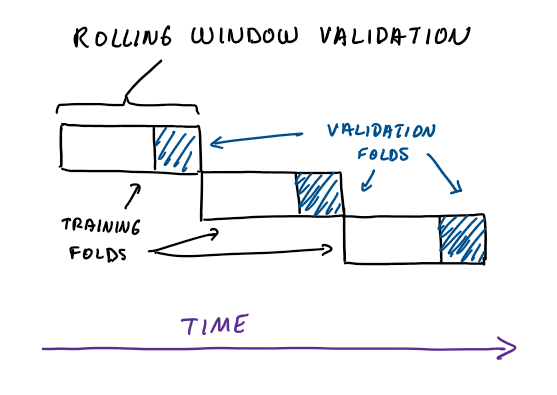
Rolling Window Validation:
In rolling window validation, the training and test sets are created by sliding a fixed-size window over the time series data. The model is trained on the past data within the window and evaluated on the subsequent data. This process is repeated until the end of the time series. This technique provides a more realistic evaluation of the model’s performance by simulating real-world scenarios.
Time-Based Validation:
In time-based validation, the data is split based on a specific time point. All data points before the chosen time point are used for training, while those after it are used for testing. This method ensures that future data is not accessible during training, preventing leakage.
Walk-Forward Validation:
Walk-forward validation extends the rolling window approach by performing iterative training and testing. The model is trained on the initial window, predictions are made for the next data point, and then the window is shifted forward. This process continues until the end of the time series. It allows the model to adapt and update its predictions as new data becomes available.
Conclusion:
When dealing with time series data in machine learning, it is essential to handle data leakage appropriately to build reliable and accurate models. By adopting strategies like train-test splits, rolling window validation, time-based validation, and walk-forward validation, we can mitigate the adverse effects of data leakage. Understanding the temporal nature of time series data and selecting appropriate validation techniques are crucial steps toward developing robust and trustworthy machine learning models in various domains.
