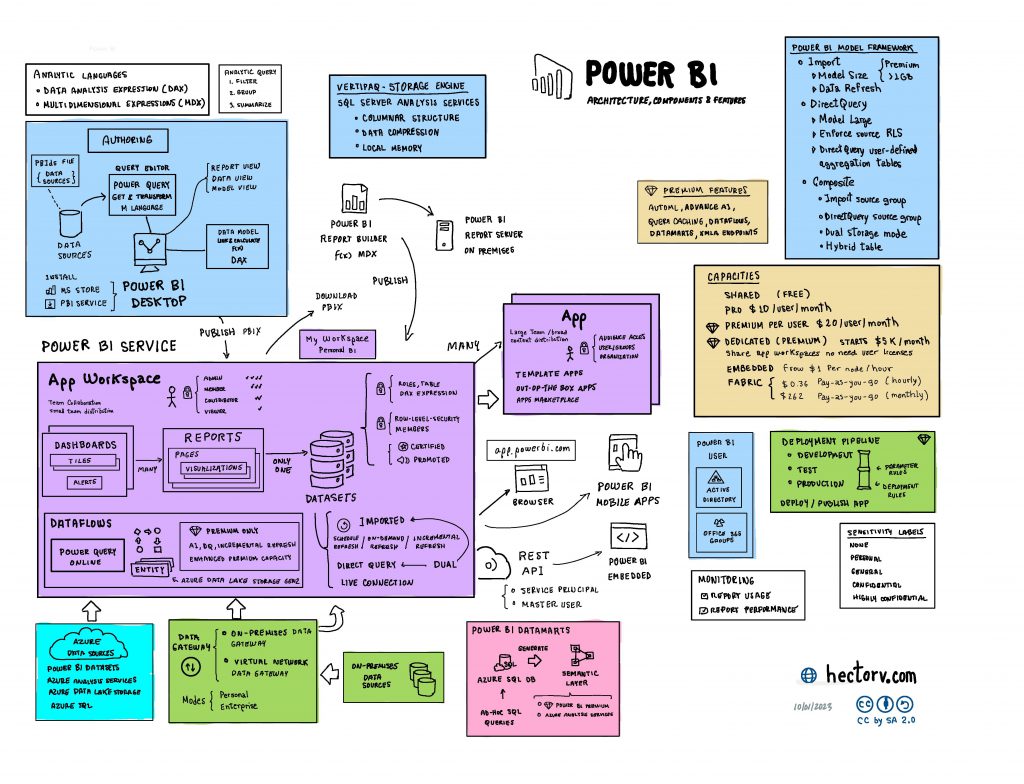
Understanding the complexities of Power BI might occasionally seem like threading through a labyrinth, considering its rich architecture, diverse components, and plethora of features. I’m delighted to present this unique Power BI diagram, which condenses all these facets into a simple, visual representation.
Below is a concise definition for each of these components:
Power BI Desktop A free application installed on your local computer that lets you connect to, transform, and visualize your data.
Power BI Service A cloud-based service (also referred to as Power BI online) where you can share and collaborate on reports and dashboards.
Power BI Mobile A mobile application available on iOS, Android, and Windows that lets you access your Power BI reports and dashboards on the go.
Power BI Gateway Software that allows you to connect to your on-premises data sources from Power BI, PowerApps, Flow, and Azure Logic Apps.
Power BI Embedded A set of APIs and controls that allow developers to embed Power BI visuals into their applications.
Power BI Premium An enhanced version of Power BI that offers additional features, dedicated cloud resources, and advanced administration.
Power BI Pro A subscription service that offers more features than the free version, like more storage and priority support.
App Workspace A collaborative space within Power BI where teams can work together on dashboards, reports, and other content, as well as manage workspace settings.
App A Power BI content package including dashboards, reports, datasets, and dataflows, shared with others in the Power BI service.
Dashboard A single canvas that displays multiple visualizations, offering a consolidated view usually across numerous datasets.
Report A multi-perspective view into a dataset, created with a Power BI Desktop and published to the Power BI service.
Paginated Report Detailed, printable reports with a fixed-layout format, optimized for printing or PDF generation.
Power BI Dataset A collection of related data that you bring into Power BI to create reports and dashboards.
Power Query A data connection technology that enables you to discover, connect, combine, and refine data across a wide variety of sources.
Dataflows A cloud-based data collection and transformation process that refreshes data into a common data model for further analysis.
Imported Mode A data connection mode in Power BI where data is imported into Power BI’s memory, allowing for enhanced performance at the cost of real-time data refresh.
Direct Query Mode A data connection mode in Power BI where queries are sent directly to the source data, allowing for real-time data analysis.
DAX (Data Analysis Expressions) A collection of functions, operators, and constants that you can use in a formula, or expression, to calculate and return one or more values.
M Language The language used in Power Query to define custom functions and data transformations.
Sensitivity Labels Labels that can be applied to data to classify and protect sensitive data based on an organization’s policies.
Power BI Datamarts A self-service analytics solution enabling users to store, explore, and manage data in a fully managed Azure SQL database.
Understanding the various components and features of Power BI is crucial for effectively leveraging its capabilities to drive data-driven decisions.
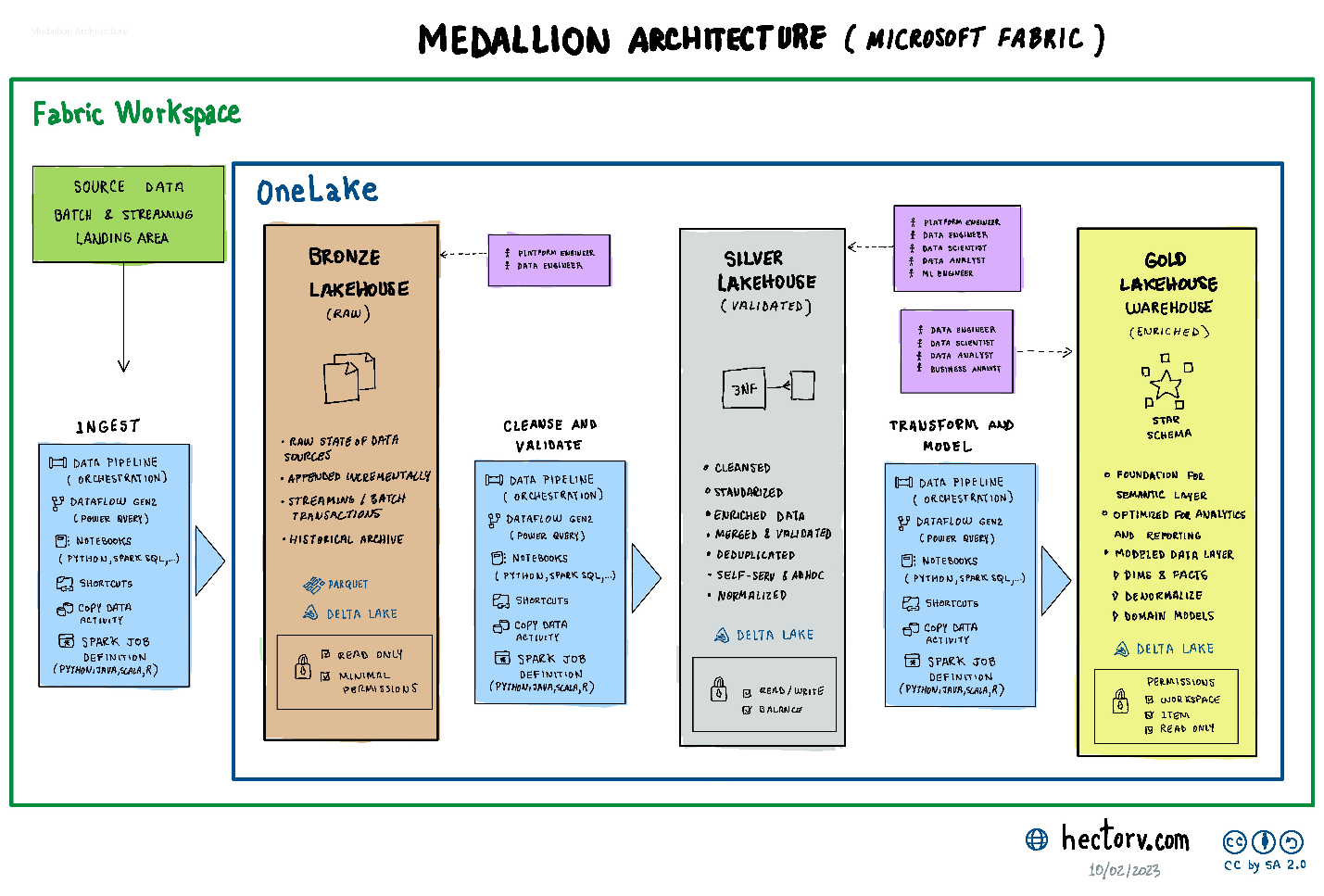
Databricks introduced the medallion architecture, a method for organizing data within a lakehouse. In this post, I will compare the different approaches available in Microsoft Fabric for ingesting and transferring data using the Medallion architecture. The medallion architecture is a multi-hop system consisting of three layers: Bronze, Silver, and Gold. As data moves through these layers, it becomes cleaner and more refined. The objective of the medallion architecture is to structure and enhance the quality of data at each level, catering to various roles and functions.
Medallion Layers
The Medallion Layers can be organized using separate folders in a lakehouse or they can separate in independent lakehouses in the same workspace depending of the use case and maintenance capacities of the organization.
Landing area
Before the data reaches the Bronze layer, it is gathered from various sources, including external vendors, in a temporary storage. Some of these sources might have file formats that are not suitable or structured for entry into the Bronze Layer. This storage can be implemented using Azure Data Lake Storage (ADLS) or Azure Blob Storage. The formats might include XML, JSON, CSV, etc.
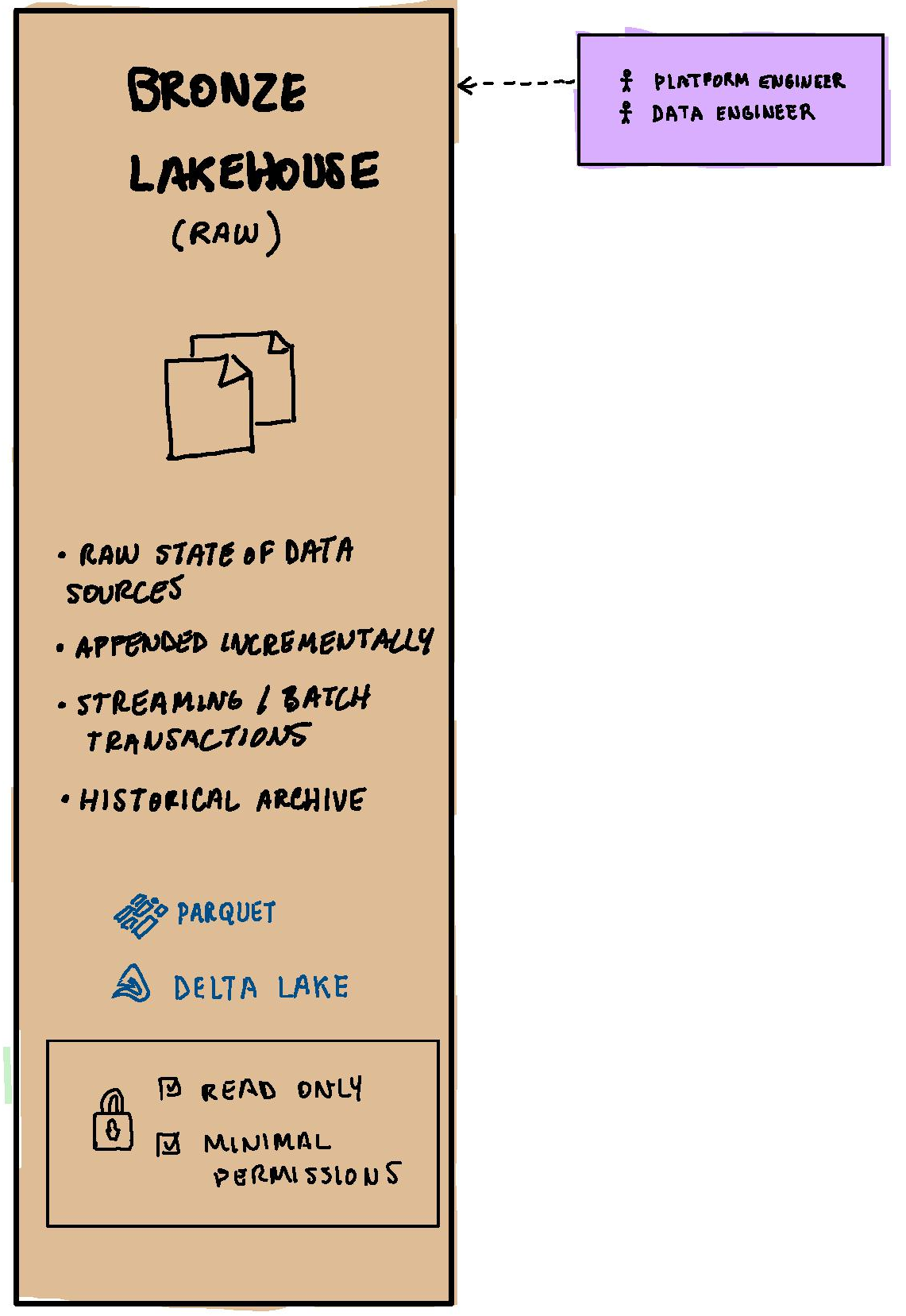
Bronze Layer
The Bronze layer represents the raw state of data sources, where both streaming and batch transactions are appended incrementally, serving as a comprehensive historical archive. For optimal storage in the bronze layer, it’s recommended to utilize columnar formats like Parquet or Delta. The beauty of columnar storage is in the way it organizes data by columns instead of rows. This arrangement not only offers enhanced compression possibilities but also streamlines the querying process, especially when working with specific data subsets.
For delta files bigger than 1TB, is recommended to divide the data in smaller partitions in order to improve performance and scalability following a folder structure year, month and day.
The data in the bronze layer is immutable or read-only and has minimal permissions on the files.
The Bronze data can be accessed by technical roles like platform engineers or data engineers. The Bronze layer might not be suitable for queries or ad-hoc analysis due to the raw nature of the data.
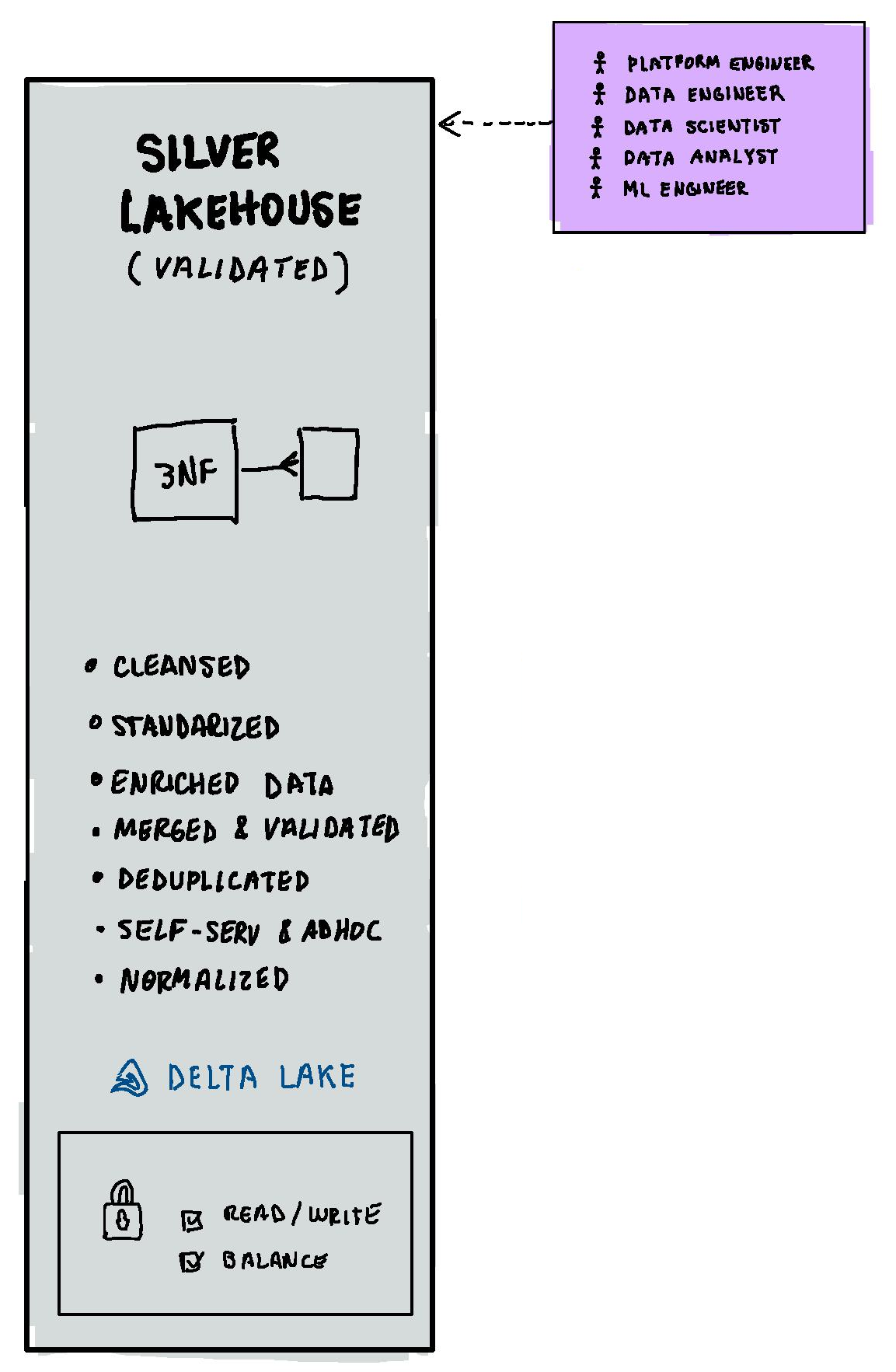
Silver Layer
The Silver layer contains validated data that has been cleansed, standardized, and enriched; it is then merged, validated, deduplicated, and normalized to 3NF (Third Normal Form). Additionally, this data can be further transformed and structured using Data Vault Model, if your schema changes to often. The Silver layer store the files in delta format and they can be load to Delta Lake tables.
The Silver layer can provide data to many roles as Platform engineers, data engineers, data scientists, data analyst and Machine Learning engineers.
The permissions in this layer can provide read/write access.
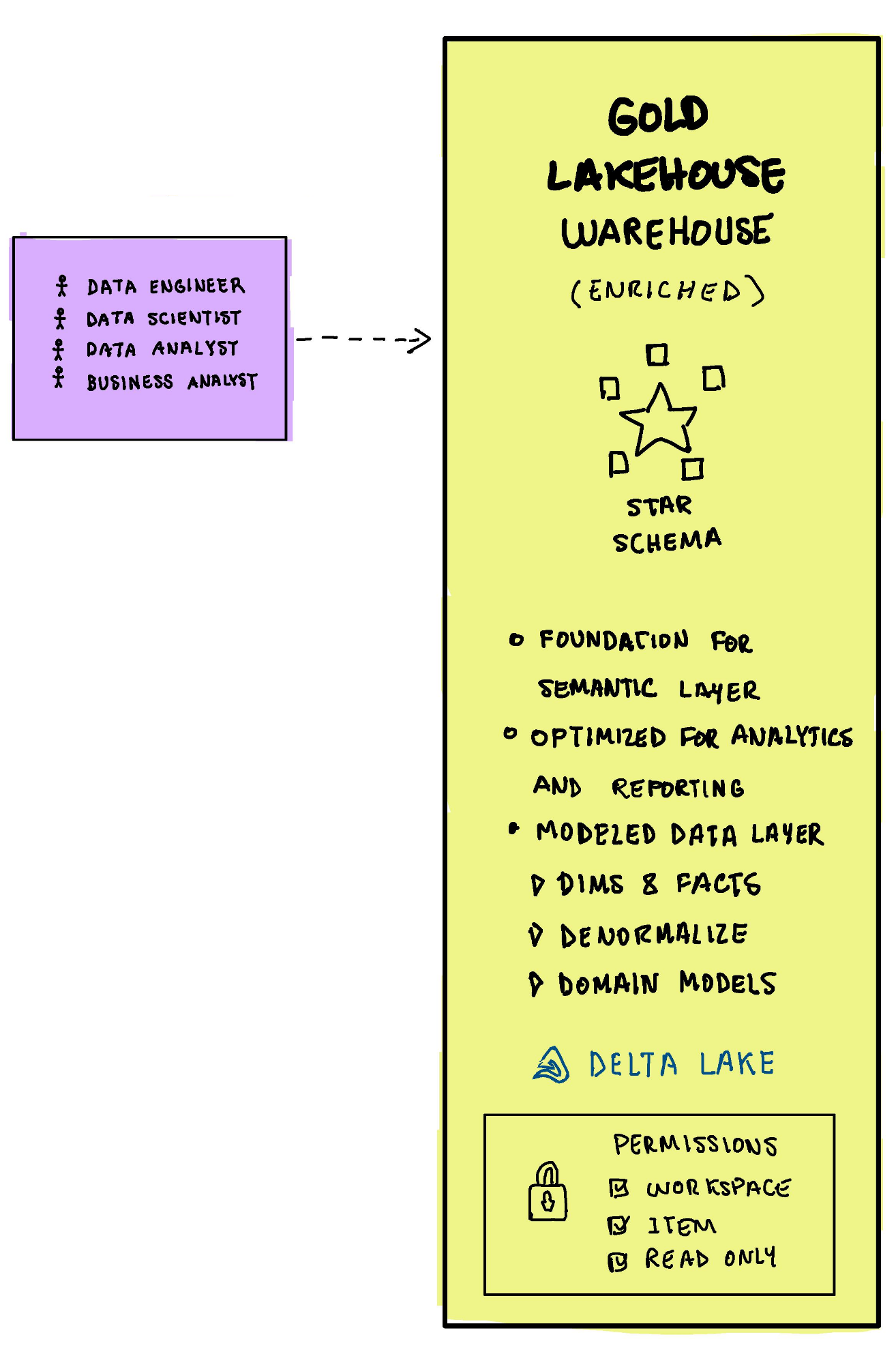
Gold Layer
The Gold layer serves as the foundation for the semantic layer, optimized for analytics and reporting. It features denormalized domain models, including facts and dimensions, conforming Kimball-style star schema, thereby forming a well-modeled data structure. The files are also store either in Delta format or Delta Lake Tables for reporting or analytics.
Data is highly governed and the permission are read only and granted at item or workspace level.
The data in the gold layer can be consumed by data Engineers, data scientist, data analyst and business analyst using tools like Power BI and Azure ML Services.
Fabric Tools
Microsoft Fabric offers a variety of tools for data ingestion and transformation, categorized into low-code and coded solutions:
No code/low code Tools:
Dataflow Gen 2, Copy Data Activity.
Coded Tools:
Fabric Notebooks, Apache Spark job definitions.
These tools can be orchestrated in a data pipeline using Data Factory.
Dataflow Gen 2
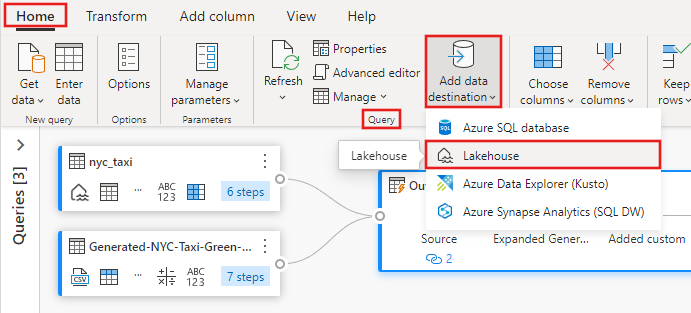
Introduced in Power BI as Power Query-like interface, it is included in Fabric as a No code, low code tool for data preparation and transformation. Dataflows can be schedule to run individually or they can be called by a data pipeline. Dataflows support more than 150+ source connectors and 300+ transformation functions. Power Query offers easy-to-use visual operations, making common data transformations accessible to a broader audience. However, when diving deeper into custom operations within dataflows, the underlying M language used by Power Query can pose challenges due to its unique syntax and steep learning curve. Dataflow Gen2 operates using Fabric capacity, and you will be billed or charged for this capacity.
The screen show below shows a dataflow for ingestion to a lakehouse using the visual Power-Query facilities:
Copy Activity in Data Factory
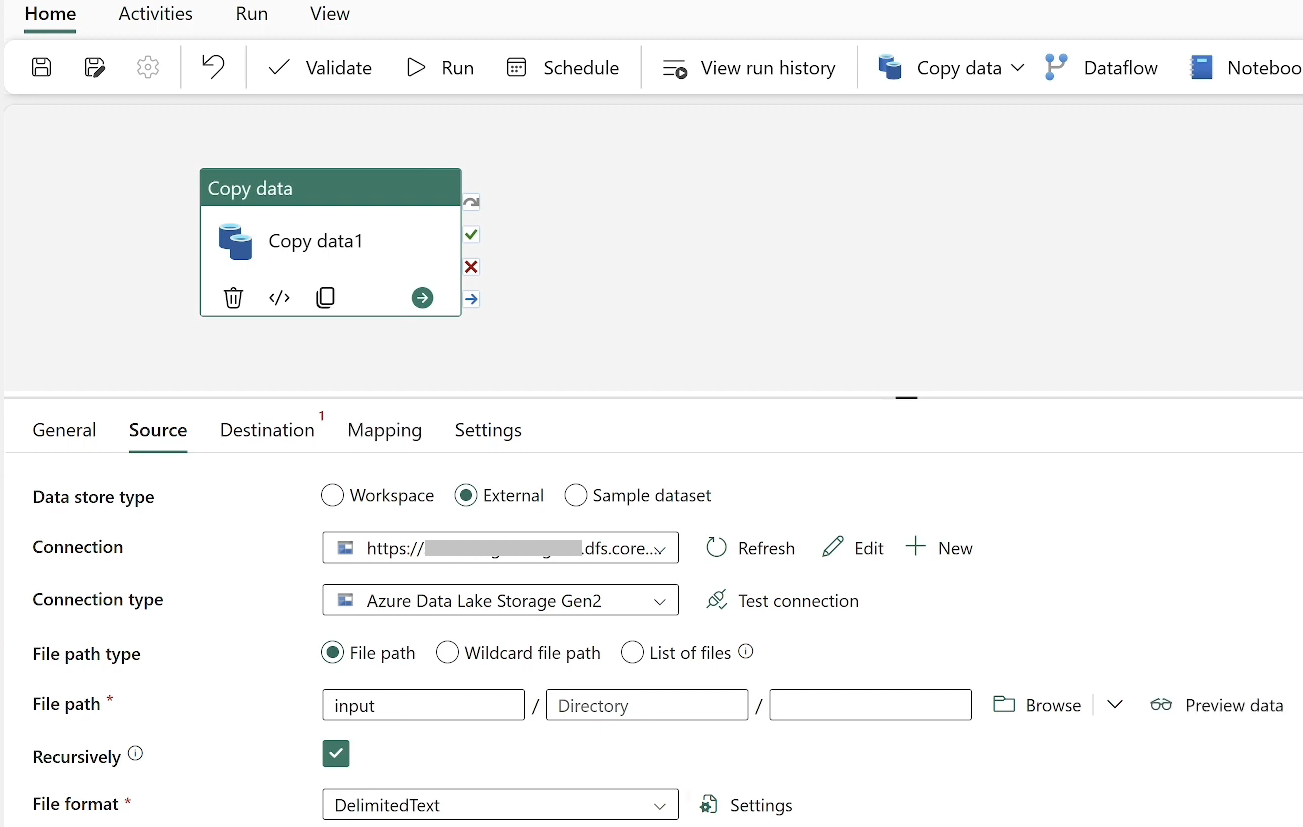
The Copy Data Activity, which can be found in both Azure Data Factory and Azure Synapse Analytics, is a powerful tool designed for efficiently transferring and mildly transforming data across numerous data storage solutions. It serves as a primary component in several data workflows that necessitate the shifting and minimal transformation of data. To run the copy activity, you’ll need to establish an integration runtime. With support for over 30 source connectors, it’s especially suitable for data ingestion into the Bronze Layer where data comes in raw state and there is no need of transformations. Data movement activity pricing is about $0.25/DIU per hour. A DIU, or Data Integration Unit, represents the resources allocated for data movement activities in Azure.
Below is a screenshot illustrating a scenario where data is copied from ADSL Gen2 to the Bronze layer in the lakehouse.
Data pipelines
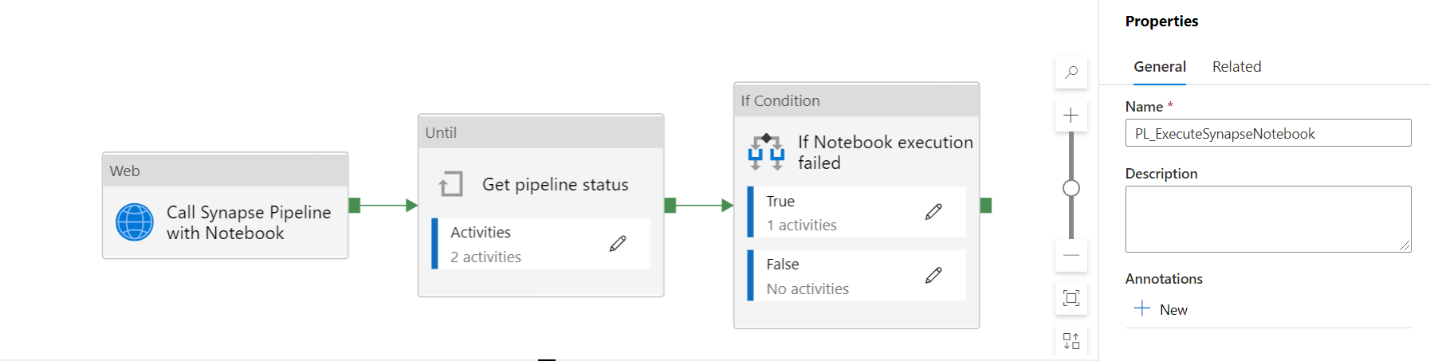
A data pipeline groups activities logically. It can load data using the copy function or transform data by invoking notebooks, SQL scripts, stored procedures, or other transformation tasks. It’s highly scalable and supports workflow logic with minimal coding. It allows pass external parameters to identify resources, which is useful to run the pipelines in life cycle environments (development, testing, productions, etc). Data pipelines can run on-demand or scheduled based on time and frequency configurations.
Below is Data Factory pipeline calling another Synapse pipeline with a notebook activity.
Fabric Notebooks
Notebooks are interactive web-based tools for developing Apache Spack jobs and machine learning experiments. They support multiple programming languages, allow mixing of code, markdown, and visualizations within a single document. Notebooks support four Apache Spark languages: PySpark (Python), Spark (Scala), SparkSQL and SparkR. Spark also provides hundreds of libraries to connect to data sources.
In PySpark, which is often utilized for distributed data processing, a DataFrame is the go-to tool for data loading and manipulation. It represents a dispersed set of data with named columns, akin to a table in a relational database or a dataframe in R or Python’s Pandas.
A notable application involves data validation when transitioning from the bronze to the silver layer. Libraries such as “Great Expectations” can be employed to authenticate data, ensuring consistency between the Silver and Bronze layers, as illustrated below.
import great_expectations as ge
# dfsales is already loaded as a PySpark DataFrame
# Convert Spark DataFrame to Great Expectations DataFrame
gedf = ge.dataset.SparkDFDataset(dfsales)
# Set up some expectations
# For demonstration purposes, let's set up the following expectations:
# 1. The "amount" column values should be between 0 and 1000.
# 2. The "date" column should not contain any null values.
# (You can set up more expectations as required.)
gedf.expect_column_values_to_be_between("amount", 0, 1000)
gedf.expect_column_values_to_not_be_null("date")
# Validate the DataFrame against expectations
results = gedf.validate()
print(results)
Apache Spark job definition
The Apache Spark Job Definition streamlines the process of submitting either batch or streaming tasks to a Spark cluster, allowing for on-demand activation or scheduled execution. It accommodates the inclusion of compiled binary files, such as .jar files from Java or Scala, and interprets files like Python’s .py and R’s .R. Much like Spark Notebooks, Spark job definitions also support a vast array of libraries.
You can craft your data ingestion or transformation code in your preferred IDE (Integrated Development Environment) using languages such as Java, Scala, Python, or R. Developing Spark job definitions within an IDE offers comprehensive development features, integrated debugging tools, extensions, plugins, and built-in testing capabilities.
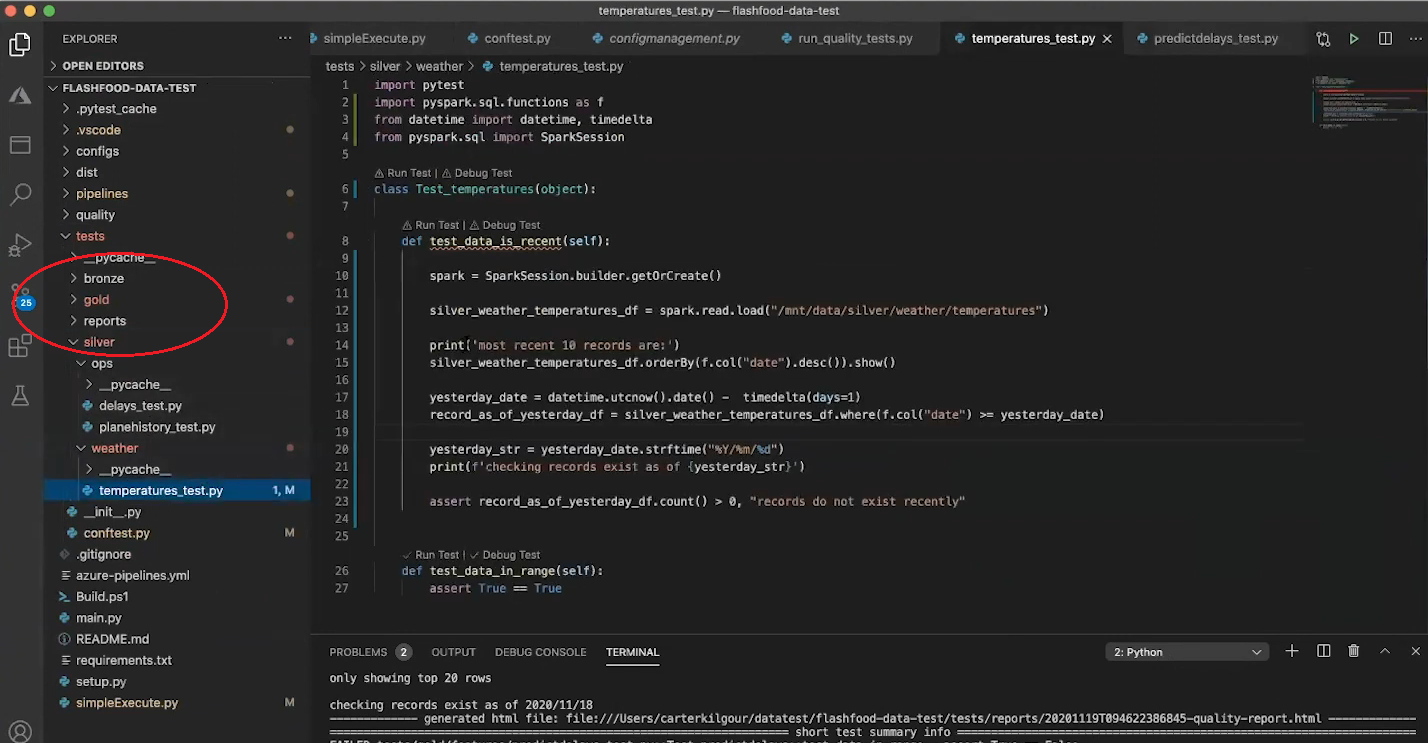
Below is a project on Data Quality Testing within the Medallion Architecture, leveraging Pytest and PySpark in Visual Studio Code.
OneLake Shortcuts
Shortcuts act as reference points to other storage locations without directly copying or altering the data. They streamline operations, allowing notebooks and spark jobs to access externally referenced data without ingesting or copying it into the lakehouse. It’s possible to establish a shortcut in the Bronze layer without actually ingesting the data. Subsequently, this can be accessed via a notebook or a job definition using the OneLake API. While shortcuts are advantageous for handling small datasets or generating brief queries and reports, they might pose challenges for intensive transformations. Doing so could lead to substantial egress charges from third-party vendors or even from referenced ADLS accounts.
Shortcuts can be used as managed tables within Spark notebooks or Spark jobs.
Low-code and no-code solutions such as ADF Copy activity and Dataflow Gen 2 offer intuitive interfaces, allowing users to ingest and process data without extensive technical knowledge. Conversely, coding platforms like Fabric Notebooks or Spark job definitions empower users to craft bespoke and adaptable solutions harnessing programming languages. The optimal choice hinges on the specific requirements, the available skill set, and the organization’s willingness to take on technical debt. While ADF Copy activity and Dataflow Gen 2 might fall short in addressing intricate or tailored needs, coded platforms like Fabric Notebooks and Spark job definitions provide versatility to address complex custom scenarios. That said, managing extensive custom code can pose maintenance challenges. For more straightforward needs, any of these tools could be apt. Yet, in many situations, the most effective strategy might involve a hybrid approach, integrating the strengths of both paradigms.
When choosing a tool for data ingestion or transformation, it’s crucial to ensure consistency in its application. Employing the same tool throughout different layers promotes easier maintenance. Avoid mixing and matching or embedding various tools or components within each other. For example, when a dataflow, power query function, or notebook invokes stored procedures, it can lead to challenges in debugging and tangled dependencies. Ideally, Data Factory should be the main orchestrator, guiding all other processes, while limiting the interplay of multiple tools within a singular data pipeline.