
In the ever-evolving landscape of data management, organizations wrestle with an array of architectural patterns to make sense of the vast ocean of information. Let’s embark on a journey through four key paradigms: Data Warehouse, Data Lake, Data Lakehouse, and the decentralized marvel known as Data Mesh.
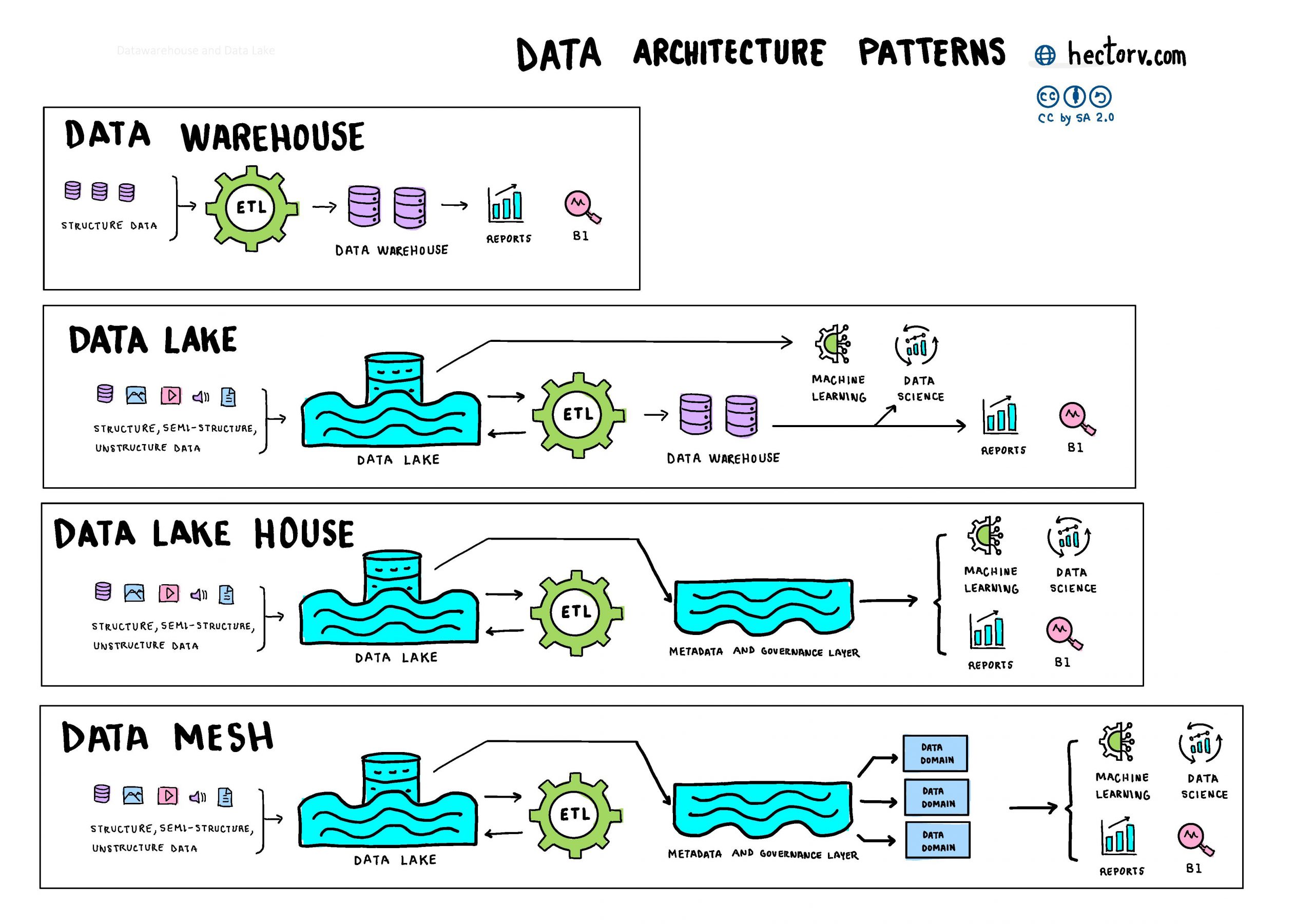
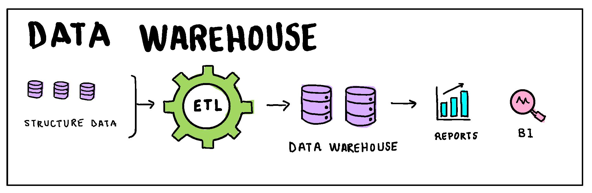
Data Warehouse: The Backbone of Structured Insights
At the core of every data-driven enterprise stands the Data Warehouse, a structured backbone that has long been a cornerstone for analytical prowess. This architectural marvel is akin to a meticulously organized library, where each piece of structured data is neatly cataloged and readily accessible.
Key Features:
- Centralization: Acting as a centralized repository, Data Warehouses integrate structured data from diverse sources, providing a unified view.
- Schema-on-Write: Data is structured and organized before being loaded through ETL processes, ensuring a consistent and reliable foundation.
- SQL Dominance: Powered by SQL queries, Data Warehouses excel in supporting business intelligence (BI) and reporting applications, generating insightful reports.
Data Lake: The Uncharted Reservoir of Possibilities
In contrast to the structured rigidity of a Data Warehouse is the uncharted wilderness of a Data Lake. Imagine a vast reservoir collecting data in its raw, unstructured, or semi-structured form. Data Lakes offer unparalleled flexibility, accommodating a diverse range of data formats.

Key Features:
- Versatility: Data Lakes embrace a multitude of data types, from structured tables to raw text and multimedia.
- Schema-on-Read: Raw, semi-structured, and unstructured data is ingested as-is, allowing for on-the-fly structuring during analysis, promoting adaptability.
- Scalable Storage: Built on scalable distributed storage systems, Data Lakes handle massive volumes of data with ease. ETL processes may still be employed for data integration with Data Warehouses.
Data Lakehouse: Harmonizing Structure and Flexibility
As organizations sought to bridge the structured elegance of Data Warehouses with the flexibility of Data Lakes, the concept of Data Lakehouse emerged. This integration of structured and raw data provides a comprehensive solution for varied analytical needs.

Key Features:
- Unified Platform: A holistic approach combining structured and unstructured data within a single platform, often involving ETL processes to maintain data integrity.
- Agile Analytics: Enables agile analytics by allowing organizations to draw insights from both raw and curated data, fostering machine learning and data science initiatives.
- Hybrid Processing: Supports both batch processing for historical analysis and real-time processing for up-to-the-minute insights. Metadata and governance layers ensure proper management and control.
Data Mesh: Decentralized Empowerment
In the era of decentralized architectures, Data Mesh emerges as a revolutionary concept. Rather than relying on a centralized data monolith, Data Mesh advocates for a domain-oriented, decentralized approach, transforming data into a product that is owned by a specific domain.

Key Features:
- Domain-Oriented Teams: Data ownership and governance are distributed across domain-oriented teams, fostering autonomy.
- Federated Architecture: A federated architecture connects distributed data products through well-defined APIs, enabling seamless collaboration. Data domains are crucial for understanding and managing the varied data structures.
- Decentralized Governance: Each domain team governs its data products, ensuring relevance, quality, and compliance. Machine learning, BI, and reports are empowered by decentralized data initiatives.
Tools
Tools commonly used in various data architecture patterns categorized by the roles or functions they serve:
- Data Ingestion and Integration:
- Apache Nifi
- Apache Kafka (for real-time data streaming)
- ETL (Extract, Transform, Load):
- AWS Glue
- Azure Data Factory
- Apache NiFi
- Apache Airflow
- SQL Server Integration Services (SSIS)
- Data Lake Storage:
- Amazon S3
- Azure Data Lake Storage
- Hadoop Distributed File System (HDFS)
- Databricks
- Data Processing and Analytics:
- Apache Spark
- Databricks
- Amazon Redshift
- Snowflake
- Google BigQuery
- Azure Synapse
- Data Warehousing:
- Data Processing and Analytics:
- Tableau
- Power BI
- MicroStrategy
Conclusion: Crafting a Future of Data Excellence
In the ever-evolving landscape of data architecture, each pattern contributes a unique thread to the fabric of data excellence. Whether it’s the structured insights of a Data Warehouse, the uncharted possibilities of a Data Lake, the harmonious integration of a Data Lakehouse, or the decentralized empowerment of a Data Mesh, organizations weave these patterns together to navigate the complexities of the data seas and derive meaningful insights. The future of data architecture lies in the artful combination of these paradigms, creating a harmonious symphony of structure, flexibility, and decentralization.